


 400-123-4321
400-123-4321
做圖像識别有很多不(bù)同的(de)途徑。谷歌最近發布了(le/liǎo)一(yī / yì /yí)個(gè)使用Tensorflow的(de)物體識别API,讓計算機視覺在(zài)各方面都更進了(le/liǎo)一(yī / yì /yí)步。
這(zhè)篇文章将帶你測試這(zhè)個(gè)新的(de)API,并且把它應用在(zài)youtube上(shàng)(可以(yǐ)在(zài)GitHub上(shàng)獲取用到(dào)的(de)全部代碼,鏈接),結果如下:

這(zhè)個(gè)API是(shì)用COCO(文本中的(de)常見物體)數據集(http://mscoco.org/)訓練出(chū)來(lái)的(de)。這(zhè)是(shì)一(yī / yì /yí)個(gè)大(dà)約有30萬張圖像、90種最常見物體的(de)數據集。物體的(de)樣本包括:

這(zhè)個(gè)API提供了(le/liǎo)5種不(bù)同的(de)模型,使用者可以(yǐ)通過設置不(bù)同檢測邊界範圍來(lái)平衡運行速度和(hé / huò)準确率。
 上(shàng)圖中的(de)mAP(平均精度)是(shì)檢測邊界框的(de)準确率和(hé / huò)回召率的(de)乘積。這(zhè)是(shì)一(yī / yì /yí)個(gè)很好的(de)混合測度,在(zài)評價模型對目标物體的(de)敏銳度和(hé / huò)它是(shì)否能很好的(de)避免虛假目标中非常好用。mAP值越高,模型的(de)準确度越高,但運行速度會相應下降。
上(shàng)圖中的(de)mAP(平均精度)是(shì)檢測邊界框的(de)準确率和(hé / huò)回召率的(de)乘積。這(zhè)是(shì)一(yī / yì /yí)個(gè)很好的(de)混合測度,在(zài)評價模型對目标物體的(de)敏銳度和(hé / huò)它是(shì)否能很好的(de)避免虛假目标中非常好用。mAP值越高,模型的(de)準确度越高,但運行速度會相應下降。
(想要(yào / yāo)了(le/liǎo)解更多跟模型有關的(de)知識:鏈接)
我決定使用最輕量級的(de)模型(ssd_mobilenet)。主要(yào / yāo)步驟如下:
1. 下載一(yī / yì /yí)個(gè)打包模型(.pb-protobuf)并把它載入緩存
2. 使用内置的(de)輔助代碼來(lái)載入标簽,類别,可視化工具等等。
3. 建立一(yī / yì /yí)個(gè)新的(de)會話,在(zài)圖片上(shàng)運行模型。
總體來(lái)說(shuō)步驟非常簡單。而(ér)且這(zhè)個(gè)API文檔還提供了(le/liǎo)一(yī / yì /yí)些能運行這(zhè)些主要(yào / yāo)步驟的(de)Jupyter文檔——鏈接
這(zhè)個(gè)模型在(zài)實例圖像上(shàng)表現得相當出(chū)色(如下圖):

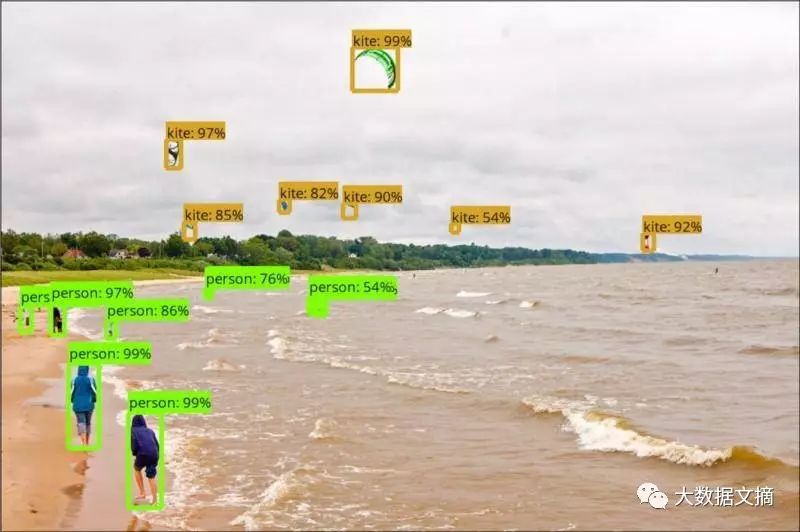
接下來(lái)我打算在(zài)視頻上(shàng)嘗試這(zhè)個(gè)API。我使用了(le/liǎo)Python moviepy庫,主要(yào / yāo)步驟如下:
首先,使用VideoFileClip函數從視頻中提取圖像;
然後使用fl_image函數在(zài)視頻中提取圖像,并在(zài)上(shàng)面應用物體識别API。fl_image是(shì)一(yī / yì /yí)個(gè)很有用的(de)函數,可以(yǐ)提取圖像并把它替換爲(wéi / wèi)修改後的(de)圖像。通過這(zhè)個(gè)函數就(jiù)可以(yǐ)實現在(zài)每個(gè)視頻上(shàng)提取圖像并應用物體識别;
最後,把所有處理過的(de)圖像片段合并成一(yī / yì /yí)個(gè)新視頻。
對于(yú)3-4秒的(de)片段,這(zhè)個(gè)程序需要(yào / yāo)花費大(dà)概1分鍾的(de)時(shí)間來(lái)運行。但鑒于(yú)我們使用的(de)是(shì)一(yī / yì /yí)個(gè)載入緩存的(de)模型,而(ér)且沒有使用GPU,我們實現的(de)效果還是(shì)很驚豔的(de)!很難相信隻用這(zhè)麽一(yī / yì /yí)點代碼,就(jiù)可以(yǐ)以(yǐ)很高的(de)準确率檢測并且在(zài)很多常見物體上(shàng)畫出(chū)邊界框。
當然,我們還是(shì)能看到(dào)有一(yī / yì /yí)些表現有待提升。比如下面的(de)例子(zǐ)。這(zhè)個(gè)視頻裏的(de)鳥完全沒有被檢測出(chū)來(lái)。

再進一(yī / yì /yí)步,繼續探索
幾個(gè)進一(yī / yì /yí)步探索這(zhè)個(gè)API的(de)想法:
嘗試一(yī / yì /yí)些準确率更高但成本也(yě)更高的(de)模型,看看他(tā)們有什麽不(bù)同;
尋找加速這(zhè)個(gè)API的(de)方法,這(zhè)樣它就(jiù)可以(yǐ)被用于(yú)車載裝置上(shàng)進行實時(shí)物體檢測;
谷歌也(yě)提供了(le/liǎo)一(yī / yì /yí)些技能來(lái)應用這(zhè)些模型進行傳遞學習。例如,載入打包模型後添加一(yī / yì /yí)個(gè)帶有不(bù)同圖像類别的(de)輸出(chū)層。
轉載36氪:http://36kr.com/p/5090812.html

